
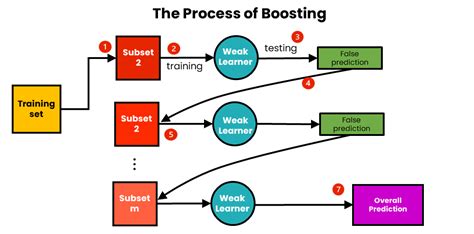

El boosting es un método de aprendizaje automático que busca mejorar la precisión predictiva combinando múltiples modelos débiles para formar un modelo más robusto y preciso. El aprendizaje conjunto refuerza la idea de la "sabiduría de las multitudes", que sugiere que la toma de decisiones de un grupo más amplio de personas suele ser mejor que la de un experto individual.
A diferencia de otros enfoques de ensamble, el boosting se centra en las instancias mal clasificadas, asignándoles pesos adicionales en cada iteración del proceso de aprendizaje. Esta estrategia permite que el modelo dé mayor importancia a las áreas donde ha cometido errores previos, corrigiendo gradualmente sus debilidades y mejorando su capacidad para generalizar a nuevos datos.
Algoritmos de boosting populares incluyen AdaBoost, Gradient Boosting, y variantes más avanzadas como XGBoost y LightGBM. La versatilidad del boosting se refleja en su aplicabilidad a problemas de clasificación, regresión y detección de anomalías, convirtiéndolo en una herramienta esencial en el arsenal del aprendizaje automático.
MACHINE LEARNING | Aprendizaje Supervisado, No Supervisado y Por Refuerzo
Fundamentos del Boosting con IA
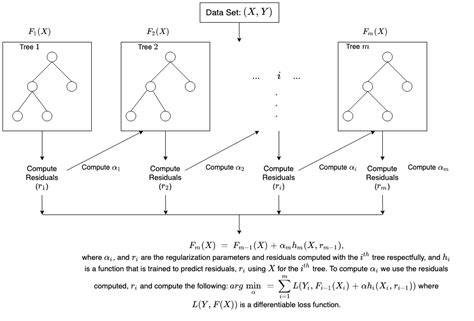
Los fundamentos del boosting radican en su enfoque de construir modelos predictivos fuertes a partir de modelos más débiles. Este método se basa en la idea central de que múltiples modelos débiles pueden combinarse para formar un modelo más robusto y preciso. En cada iteración del proceso de boosting, el algoritmo asigna pesos a las instancias mal clasificadas, permitiendo que los modelos subsiguientes se centren en corregir los errores previos.
Algoritmos emblemáticos como AdaBoost y Gradient Boosting implementan este principio, generando una serie de modelos que se combinan de manera ponderada para mejorar la capacidad predictiva del conjunto. Este enfoque iterativo y adaptativo ha demostrado ser altamente efectivo, proporcionando una mejora sustancial en la precisión de la predicción y destacándose como un componente esencial en el campo del aprendizaje automático.
Mejoras en la Precisión Predictiva
La precisión predictiva en el contexto del boosting emerge como uno de sus atributos más destacados. Esta técnica de aprendizaje automático se distingue por su capacidad para mejorar de manera significativa la precisión de las predicciones. Al asignar pesos a las instancias mal clasificadas en cada iteración, el modelo se enfoca en corregir sus errores anteriores, permitiendo una adaptación continua y refinamiento de su capacidad predictiva.
Esta atención a las áreas problemáticas resulta en modelos más robustos que logran una generalización efectiva a nuevos datos. La naturaleza iterativa del boosting, combinada con la corrección enfocada de errores, reduce la tendencia al sobreajuste y mejora la capacidad del modelo para capturar patrones complejos en los datos, resultando en una precisión predictiva excepcional en una variedad de problemas de aprendizaje automático.
Adaptabilidad a Diferentes Dominios
La adaptabilidad de las mejoras a diferentes dominios es una de las fortalezas particulares del campo del aprendizaje automático. Este método de instalación demuestra una versatilidad excepcional para resolver una variedad de problemas en una variedad de áreas. Desde problemas de clasificación hasta tareas de regresión y detección de anomalías, la amplificación se puede utilizar con éxito en una variedad de dominios.
La capacidad de adaptarse a la complejidad inherente de los datos, combinada con la capacidad de manejar conjuntos desequilibrados, la convierte en una herramienta invaluable en campos tan diversos como la medicina, las finanzas, la industria y más. La ventaja del impulso radica no solo en su aplicabilidad a muchos tipos diferentes de datos, sino también en su eficacia para mejorar la precisión en situaciones en las que otros métodos de aprendizaje automático pueden tener limitaciones. Esta flexibilidad la convierte en una opción poderosa y de uso frecuente para resolver problemas del mundo real.
Interpretabilidad del Modelo
A pesar de su complejidad, la exposición brinda la oportunidad de interpretar patrones sorprendentes que son importantes en múltiples contextos. Esta propiedad se deriva de la capacidad del algoritmo para asignar pesos a los objetos durante el proceso iterativo. La capacidad de explorar estos pesos hace que sea más fácil comprender la importancia relativa de cada característica en la solución del modelo.
Este enfoque transparente no sólo proporciona información valiosa sobre la lógica del modelo, sino que también proporciona un medio para explicar los supuestos del modelo a usuarios no técnicos. Esta interpretación es un aspecto importante en aplicaciones donde la transparencia y la comprensión son importantes, como la atención médica o las finanzas, lo que permite a los usuarios comprender mejor y confiar en las soluciones del modelo de consolidación.
Retos y Consideraciones Éticas
Los avances en inteligencia artificial ofrecen beneficios significativos, pero no exentos de desafíos y consideraciones éticas. Uno de los principales problemas es que puede haber sesgos en los datos de entrenamiento que pueden amplificarse durante el proceso de entrenamiento. Interpretar los resultados puede resultar difícil porque los patrones complejos pueden resultar difíciles de entender. Además, se requieren grandes cantidades de datos, lo que puede generar preocupaciones sobre la privacidad.
Desde un punto de vista ético, la equidad y la no discriminación en el aprendizaje automático son muy importantes, ya que los modelos pueden perpetuar involuntariamente los sesgos existentes.
Bagging vs. Boosting
El bagging y el boosting son dos tipos principales de métodos de aprendizaje por conjuntos. En el bagging, los alumnos débiles se entrenan en paralelo, pero en el boosting, aprenden secuencialmente. Esta redistribución de las ponderaciones ayuda al algoritmo a identificar los parámetros en los que debe centrarse para mejorar su rendimiento.
AdaBoost, que significa "algoritmo de boosting adaptativo", es uno de los algoritmos de boosting más populares, ya que fue uno de los primeros de su tipo. Otra diferencia en la que se distinguen el bagging y el boosting son los escenarios en los que se utilizan.
Bagging vs Boosting
Aplicaciones Prácticas del Boosting
La técnica de boosting se utiliza en muchos sectores, proporcionando información tanto sobre el valor real como sobre perspectivas interesantes, como en los GRAMMY Debates with Watson.
- Sanidad: El boosting se ha utilizado para formar predicciones de datos médicos. Por ejemplo, la investigación muestra que los métodos de conjunto se han utilizado para una serie de problemas bioinformáticos, como la selección de genes y/o proteínas para identificar un rasgo específico de interés. Más concretamente, esta investigación profundiza en su uso para predecir la aparición de diabetes basándose en varios predictores de riesgo.
- TI: El boosting también puede mejorar la precisión y la exactitud de los sistemas de TI, como los sistemas de detección de intrusiones en la red. Mientras tanto, esta investigación analiza cómo el boosting puede mejorar la precisión de la detección de intrusiones en la red y reducir las tasas de falsos positivos.
- Entorno: Los métodos de conjuntos, como el boosting, se han aplicado en el campo de la detección remota. Más concretamente, esta investigación muestra cómo se ha utilizado para cartografiar los tipos de humedales dentro de un paisaje costero.
- Finanzas: El boosting también se ha utilizado con modelos de deep learning en el sector financiero, automatizando tareas críticas, como la detección del fraude, las evaluaciones de riesgo crediticio y los problemas de valoración de opciones. Esta investigación demuestra cómo se ha aprovechado el boosting, entre otras técnicas de machine learning, para evaluar el riesgo de impago de los préstamos.
Lead Scoring Predictivo
El lead scoring predictivo se sustenta en modelos de machine learning y análisis estadístico para estimar con precisión la probabilidad de conversión de cada prospecto. En lugar de depender de reglas estáticas predefinidas por los equipos de marketing o ventas, este enfoque aprende de forma continua de patrones históricos de comportamiento y datos demográficos. Así, a medida que se incorporan nuevos registros o interacciones, el sistema ajusta automáticamente sus predicciones, ofreciendo calificaciones cada vez más afinadas.
En comparación con los métodos tradicionales, el scoring predictivo despliega una automatización constante que no requiere redefinir manualmente cada criterio, mejora la precisión al considerar cientos de variables, y reduce el impacto de sesgos subjetivos. De ello resulta una alineación más estrecha entre marketing y ventas, al entregar listados de prospectos optimizados según su verdadero potencial.
¿Cómo funciona el análisis predictivo?
Para poner en marcha un sistema de scoring predictivo, lo primero es asegurar la recolección y preparación adecuada de los datos. Los equipos deben integrar información demográfica y firmográfica (como la industria, el tamaño y la ubicación de la empresa), datos de comportamiento (visitas al sitio web, interacciones por correo, descargas de recursos y participación en webinars) y registros transaccionales o de CRM (historial de compras y valor del cliente).
Una vez desplegado, el modelo otorga a cada lead un puntaje de conversión que puede situarse entre 0 y 100, o expresarse como un porcentaje. Con base en estos valores, se segmentan los prospectos en categorías de alta prioridad -aquellos con mayor probabilidad de conversión, listos para un contacto inmediato-, prioridad media, para los que conviene nutrirlos con más contenido, y prioridad baja, que permanecerán en flujos de marketing automatizado.
Generación del Score y Segmentación
Una vez entrenado el modelo, se aplica a nuevos leads o a la base histórica para obtener un puntaje de probabilidad de conversión, típicamente entre 0 y 100 o entre 0 % y 100 %.
- High Priority Leads (80 - 100): listos para contacto inmediato.
- Medium Priority (50 - 79): requieren nutrición adicional.
- Low Priority (< 50): menos urgentes, quedan en flujos de marketing automatizado.
Implementación Paso a Paso
Antes de cualquier despliegue, conviene definir claramente los objetivos y métricas: desde la tasa de conversión SQL→Oportunidad hasta los ingresos atribuibles. A continuación, se audita la calidad de los datos en el CRM y las plataformas de marketing, integrando las herramientas clave (como Salesforce, HubSpot, Marketo o Google Analytics) y configurando pipelines automáticos de limpieza y enriquecimiento.
El despliegue debe acompañarse de tests A/B que comparen un grupo control (sin scoring o con scoring tradicional) con otro que reciba las recomendaciones predictivas. Finalmente, es imprescindible contar con dashboards de monitoreo que muestren el rendimiento del modelo (AUC, CPC, CAC), reentrenarlo periódicamente -idealmente cada uno a tres meses- y alimentar un ciclo de retroalimentación con el equipo de ventas.
| Proveedor | Características | Nivel técnico |
|---|---|---|
| HubSpot | Integración nativa CRM-Marketing, interfaz sin código, paneles preconfigurados. | Bajo - Medio |
| Salesforce Einstein | Modelos integrados, despliegue en escala, requiere licencia Einstein Analytics. | Medio - Alto |
| MadKudu | Especializado en SaaS B2B, segmentación avanzada, scoring granular por segmentos. | Medio |
| Infer | Data Science como servicio, enfoque en data-driven marketing y ventas, API flexible. | Alto |
¿Cómo usar el Lead Scoring predictivo para identificar Leads de alto potencial?
El primer paso consiste en delimitar el perfil de cliente ideal (ICP), estableciendo criterios de vertical, tamaño y zona geográfica, junto con indicadores de valor como el LTV y facturación promedio. Cuando un lead supera el umbral predeterminado, conviene activar alertas en tiempo real que avisen a los SDRs para que inicien el contacto inmediatamente.
Este seguimiento debe complementarse con envíos de recursos personalizados -whitepapers, demos y casos de éxito- ajustados al perfil y al nivel de interés mostrado. En paralelo, la nutrición inteligente de leads se realiza mediante flujos de correo dinámico, cuyos contenidos se adaptan al puntaje del prospecto, y campañas de retargeting en redes sociales para mantener su atención.