En el mundo actual, el software es omnipresente. Desde chatear con amigos hasta comprar en línea o escuchar música, dependemos del software para casi todo. Cada software posee una arquitectura que, bien o mal diseñada, incluye elementos que definen su estructura y funcionamiento. Cuando la resolución de problemas es compleja, la fase de diseño arquitectural debe ser intencional.
La arquitectura hexagonal, también conocida como patrón de puertos y adaptadores, propone una metodología de diseño para sistemas complejos que facilita alcanzar los objetivos de calidad.
Aprende Arquitectura Hexagonal en 10 minutos
En este artículo vamos a construir una pequeña aplicación de gestión de tareas utilizando Arquitectura Hexagonal (Ports & Adapters) con Java y Spring Boot. La idea es aislar completamente la lógica de negocio (nuestro dominio) del framework y detalles de infraestructura (como el acceso a base de datos o los controladores REST). Esto nos permite tener un dominio limpio, fácil de testear y muy adaptable.
La clave de esta arquitectura es la separación, que implica un bajo acoplamiento entre capas, lo que a su vez resulta en una mayor mantenibilidad y la posibilidad de realizar pruebas unitarias de manera más sencilla. Además, favorece la alta cohesión.
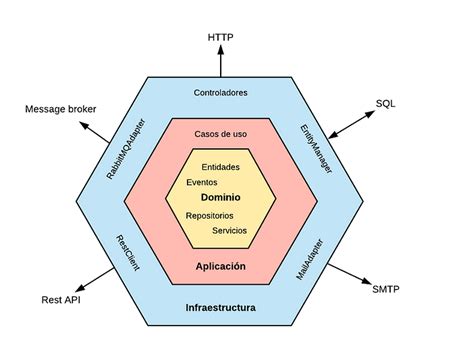
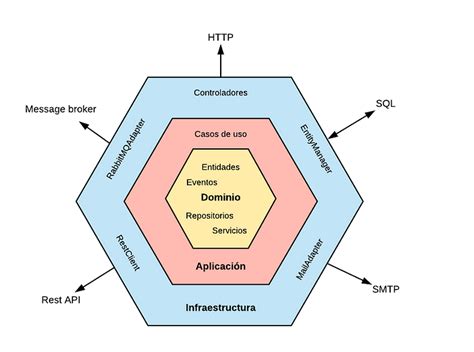
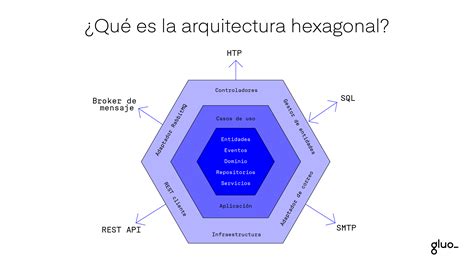
Representación de la Arquitectura Hexagonal o Puertos y Adaptadores.
¿Qué es la Arquitectura Hexagonal?
La arquitectura hexagonal aísla la lógica de negocio (el dominio) del resto de la infraestructura. De esta forma, cualquier cambio en la forma en que se llama al servicio, los repositorios de datos o el framework no afecta la lógica de negocio.
Aunque se representa como un hexágono, la forma no limita el número de interacciones entre las capas. Cada lado del hexágono representa un puerto al que podemos conectarnos a través de un adaptador.
Capas de la Arquitectura Hexagonal
- Capa de Dominio: Contiene la lógica central de la aplicación, incluyendo reglas de negocio, entidades y valor de objetos.
- Capa de Aplicación: Actúa como un intermediario entre la capa de dominio y la capa de infraestructura.
Ventajas Clave
- Desacoplamiento: Las capas están altamente desacopladas, lo que facilita cambios en una capa sin afectar a las demás.
- Pruebas Unitarias: Al separar claramente las capas, es más fácil realizar pruebas unitarias y pruebas de integración.
Implementación en Spring Boot
Para implementar la arquitectura hexagonal en un proyecto de e-commerce con Spring Boot, es fundamental respetar el orden de las capas. Consideremos el caso de uso de registrar un usuario:
- Implementamos un adaptador (por ejemplo, un controlador) que recibe una petición HTTP para registrar un usuario.
- Este controlador/adaptador necesita utilizar un "caso de uso" de la capa de aplicación (por ejemplo, la interfaz UserSignIn y la clase UserSignInImpl) para registrar al usuario. Se define una interfaz y una clase que la implementa siguiendo el Principio de Inversión de Dependencias (la D de los principios SOLID), que establece que es mejor acoplarse a contratos (UserSignIn) y no a implementaciones concretas (UserSignInImpl).
- Este caso de uso de la capa de aplicación necesita crear una entidad usuario (por ejemplo, la clase User) y almacenarla en un repositorio (por ejemplo, la interfaz UserRepository). Estos dos últimos elementos pertenecen a la capa de dominio, que es el núcleo del sistema en una arquitectura limpia.
Con este diseño, se obtienen varias ventajas:
- El caso de uso de registrar un usuario podría utilizarse desde distintos lugares que no sean la clase UserController.
- El caso de uso de registrar un usuario podría implementarse de diferentes maneras.
- El caso de uso de registrar un usuario podría almacenar al usuario en una base de datos documental (MongoDB) o relacional (PostgreSQL), gracias al principio de inversión de dependencias.
Ejemplo Práctico: Cambiar el Nombre de un Cliente
Consideremos un API REST con endpoints para obtener y crear clientes. Ahora, supongamos que necesitamos permitir cambiar el nombre de un cliente. ¿Qué cambios serían necesarios?
Primero, se crearía un endpoint con el método PUT, cuya ruta incluya el ID del cliente y que reciba el nuevo nombre en el cuerpo de la petición. Luego, se recuperaría el cliente con el ID proporcionado, se cambiaría el nombre y se volvería a persistir.
Dado que hay varias operaciones atómicas que se reutilizan en la lógica de negocio (como buscar un cliente por ID y actualizar un cliente), es útil encapsular estos casos de uso en objetos. Esto permitiría reutilizar la lógica y simplificar el mantenimiento del código. Para esto, podemos basarnos en CQRS (Command-Query Responsibility Segregation). Primero, construimos nuestro modelo de casos de uso. Luego, necesitamos una forma única de ejecutar estos casos de uso, modelando un UseCaseBus que se inyectaría donde necesitemos ejecutar un caso de uso. El UseCaseBus se encargará de saber cómo se ejecuta cada Command y cada Query.
Ubicación de los Objetos
Estos objetos pueden extraerse a un proyecto de arquitectura aparte o colocarse en un módulo de arquitectura aparte. Se puede crear un wrapper para el contexto, para poder utilizar la inyección de dependencias dentro de la capa de dominio sin acoplarse a Spring.
La lógica de negocio debe ser agnóstica a los detalles de las implementaciones (la base de datos, la forma de ejecutarla a través de una API REST, el framework utilizado, etc.). Por lo tanto, es recomendable colocar estas clases en un módulo de arquitectura. Esto permite cambiar cualquiera de estas cosas sin afectar la lógica de negocio.
Las clases Query y Command no tienen lógica, pero sirven para diferenciar entre Query y Command. Desde un Command, se deberían poder ejecutar tanto otros commands como queries, pero desde una Query, no se deberían poder ejecutar comandos.
Caso de Uso: Recuperar un Cliente por ID
El código para recuperar un cliente por su ID es sencillo. Se utilizan dos constructores: uno protected para proveer un mock del puerto en los tests unitarios, y uno público que acepta un ID de cliente y utiliza el método locate() para obtener una instancia del puerto secundario en tiempo de ejecución. Aquí es donde se utiliza el wrapper del contexto (ServiceLocator) para "inyectar la dependencia" de forma desacoplada del contexto de aplicación de Spring.
Caso de Uso: Cambiar el Nombre del Cliente
Para cambiar el nombre del cliente, se orquestan las llamadas y la lógica que no tenga un caso de uso propio en otro objeto, como el adaptador primario. El adaptador ya no depende del puerto secundario, sino que necesita ejecutar casos de uso. Se cambia la lógica para llamar a los casos de uso en lugar de ir directamente al adaptador secundario.
Los casos de uso permiten tener lógicas acotadas y probadas, y reutilizar estas para componer otros casos de uso más complejos, facilitando la comprensión y el mantenimiento del sistema al generar un código más expresivo y fácil de comprender.
Ventajas de la Arquitectura Hexagonal
La arquitectura hexagonal ofrece numerosas ventajas:
- Aislamiento del Dominio: La lógica de negocio está aislada de la infraestructura, lo que facilita los cambios y el mantenimiento.
- Testabilidad: Facilita la realización de pruebas unitarias gracias al bajo acoplamiento entre capas.
- Flexibilidad: Permite cambiar la implementación de los casos de uso sin afectar otras partes del sistema.
- Reutilización: Los casos de uso pueden reutilizarse en diferentes contextos y adaptadores.
Configuración Externalizada
La configuración externalizada se basa en la idea de que toda la información variable o sensible de un servicio debe residir fuera del propio binario. Esto reduce la probabilidad de que contraseñas o API keys terminen en repositorios públicos o logs de build. Además, permite cambiar parámetros sin recompilar el servicio, ahorrando tiempo y riesgos de errores.
Existen tres aproximaciones habituales: variables de entorno, ficheros externos y servicios de configuración centralizada. Para grandes ecosistemas de microservicios, un servidor de configuración se convierte en una pieza fundamental.
Este flujo se repite para otros servicios, manteniendo la configuración en un lugar central y versionado.
Seguridad en Microservicios
En la autenticación basada en tokens, un cliente envía credenciales a un servicio de autenticación. Tras validar las credenciales, dicho servicio emite un token. El filtro se encarga de interceptar cada solicitud HTTP, extraer el token (si existe) y validar su legitimidad. Si es válido, el filter “deja pasar” la ejecución al controlador protegido.
OAuth es un protocolo de autorización que permite a los usuarios compartir recursos protegidos con aplicaciones de terceros sin ceder sus credenciales directamente.
En este ejemplo, se han separado los casos de uso tanto en la capa de 'infraestructure' (entrada - RestControllers) como en la capa de 'application'. Se utiliza un servicio específico para cada caso de uso: uno dedicado a la creación de tareas (createTask) y otro encargado de la obtención de todas las tareas (getAllTasks). Esta separación permite una mayor modularidad y separación de responsabilidad en cada componente, facilitando el mantenimiento, la escalabilidad y las pruebas unitarias. Al aislar cada caso de uso, evitamos mezclas innecesarias de lógica y conseguimos una arquitectura más alineada con los principios de diseño limpio y la responsabilidad única.
En este ejemplo utilizaremos una B.D. en memoria H2.
En este ejemplo no vamos a utilizar DDD (Domain Driven Design) para no complicar demasiado y centrarnos directamente en las ventajas que aporta la Arquitectura Hexagonal. El uso de DDD en la Arquitectura Hexagonal es opcional y se recomienda su uso cuando el dominio tiene bastante lógica. Cuando las entidades de dominio actúan casi en su totalidad como DTOs (Data Transfer Objects) y no tienen lógica, se suele obviar el uso de DDD y se dice que el proyecto tiene un Dominio Anémico.
Separación entre el modelo de dominio y el modelo de base de datos:
Se debe mantener separado el modelo de dominio (la clase 'Task' que representa la lógica del negocio) del modelo de persistencia ('TaskEntity', usado por JPA). Aunque puedan parecer similares, tienen responsabilidades distintas: el dominio expresa reglas y conceptos del negocio, mientras que la definición de la entidad de persistencia depende de como se guardan los datos físicamente en B.D. Esto se ve más claramente si se utilizase DDD ya que la entidad de dominio 'Task' tendría lógica y se diferenciaría cláramente de la entidad de persistencia que carecería de dicha lógica.
Esta separación evita que detalles técnicos (como anotaciones JPA, IDs autogenerados o relaciones) contaminen la lógica del negocio. También nos permite modificar la persistencia sin tocar el núcleo de la aplicación, e incluso cambiar de base de datos o usar almacenamiento alternativo sin afectar al dominio. Esto no es casual: forma parte del principio de independencia del dominio que promueve la 'Arquitectura Hexagonal'.
Gracias a esta separación, las capas de dominio y aplicación no dependen de ningún framework ni librería externa, lo que las hace más testeables, reutilizables y desacopladas. Podríamos usar exactamente el mismo núcleo de negocio en una app de consola, escritorio, REST o eventos, simplemente conectando adaptadores distintos.